
Subprocess¶
Usually an activity is carried out in a process step which we integrate via the activity repository. But in BPM you can also embed entire processes in one process step. This allows you to display large processes in a more compact way and thus reduce the visual complexity. In the next image the process step SubProcess contains a subprocess.
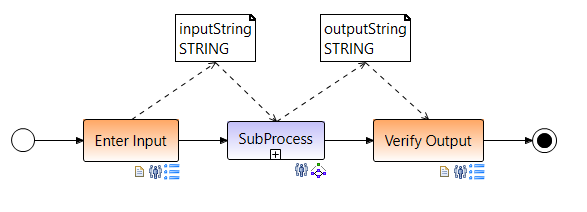
A subprocess can contain a collection of activities (process steps) or another subprocess again. This leads to a hierarchical process structure in which, however, no cycles are allowed. The following figure shows a subprocess with input and output parameters.
A subprocess is described like a normal process by its own process model and, as with activities, is also added to a parent process using drag & drop. It can be referenced in the corresponding parent process template (referenced process) or be embedded (embedded process). This means that the subprocess is either managed as independent process template and can be used outside of the parent process template, or it will be physically in the parent process template integrated. Therefore, the referenced templates are loaded onto the AristaFlow server and managed by the Template Manager, whereby the embedded templates are only saved locally. In the case of referenced subprocess, the execution of the corresponding process instance can be split off as is the case with a forked process. As a result, such process instances run independently and decoupled from the parent process, as if they had been started separately.
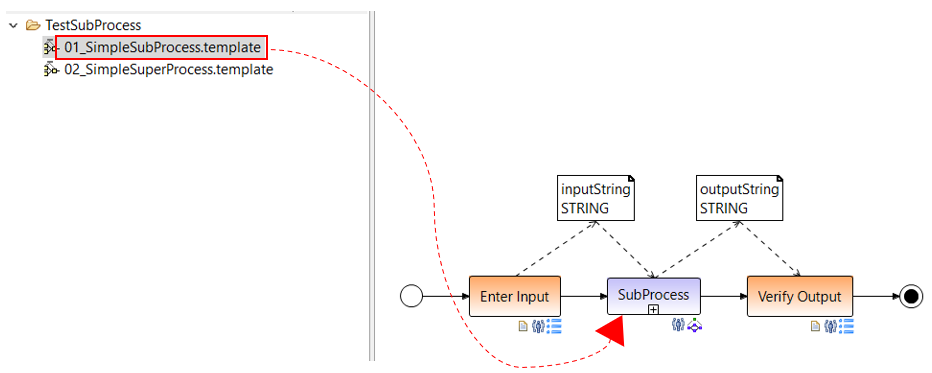
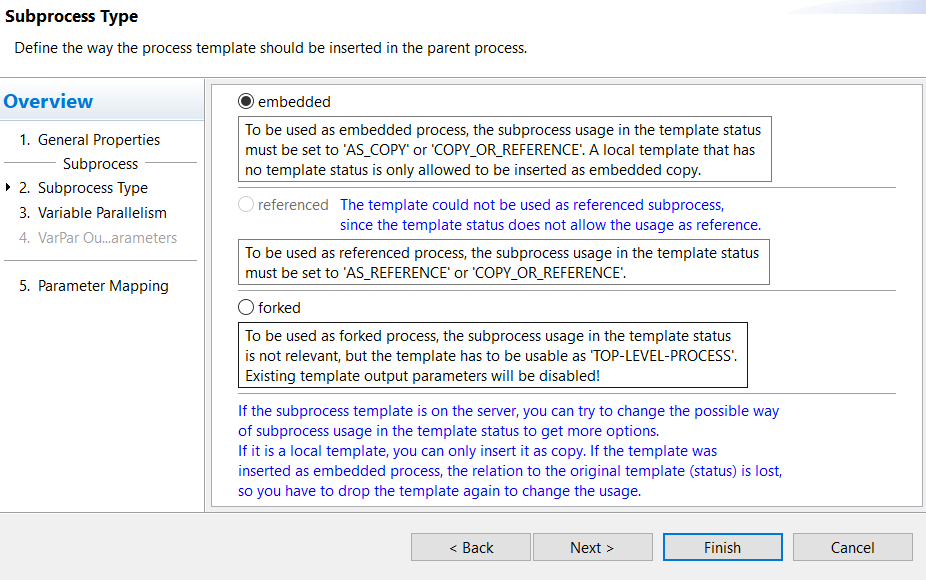
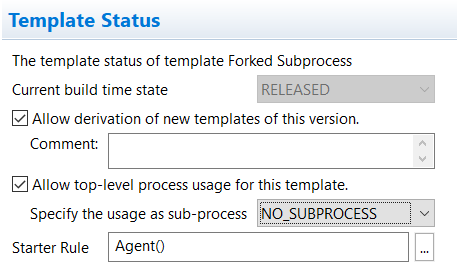
After the insertion, a wizard window opens in which you can select the type of subprocess embedded, referenced or forked. You can choose between different forms of embedding a subprocess in the main process as well as execution modes.
Subprocess Type: embedded, referenced, forked¶
-
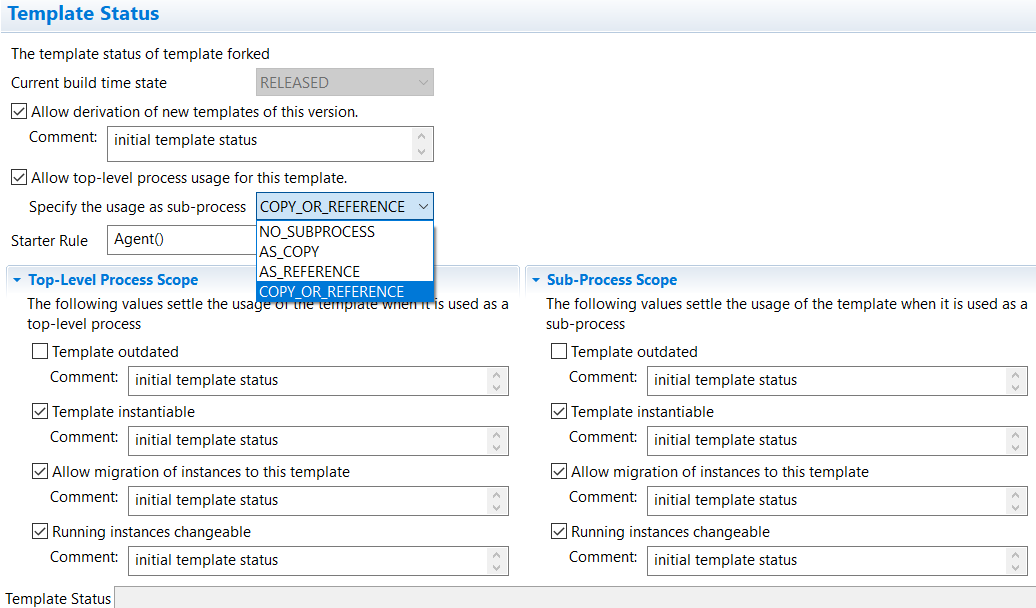
Embedded: To be used as embedded process, the subprocess usage in the template status must be set to AS_COPY or COPY_OR_REFERENCE. A local template which is not uploaded to server is only allowed to be inserted as embedded copy.
-
Referenced: If the template status of the subprocess is set to AS REFERENCE or COPY_OR_REFERENCE, then it can be referenced from the parent process.
In both cases, embedded and referenced, the parent process waits for the subprocess to end after the call.- The distinction between embedded and referenced types is that the embedded process can be changed as desired by parent process, the changes are applied after saving. But the relation to original template is lost so that the changes made by the parent process are not adopted from the original template. However, in the case of referenced processes, the changed subprocess must be referenced again.
- The distinction between embedded and referenced types is that the embedded process can be changed as desired by parent process, the changes are applied after saving. But the relation to original template is lost so that the changes made by the parent process are not adopted from the original template. However, in the case of referenced processes, the changed subprocess must be referenced again.
-
Forked: To be used as forked process the template must be able to be execute as stand-alone process i.e. in the template status the TOP-LEVEL-PROCESS usage must be enabled. The subprocess usage is not relevant for forked processes (see the following image).
- Both the referenced and the forked processes can only be integrated from the template manager.
In the case of forked-insertion, the parent and child processes are executed in parallel, and the execution branches out. In this respect, forked is not an ordinary subprocess but a called process that runs in parallel.
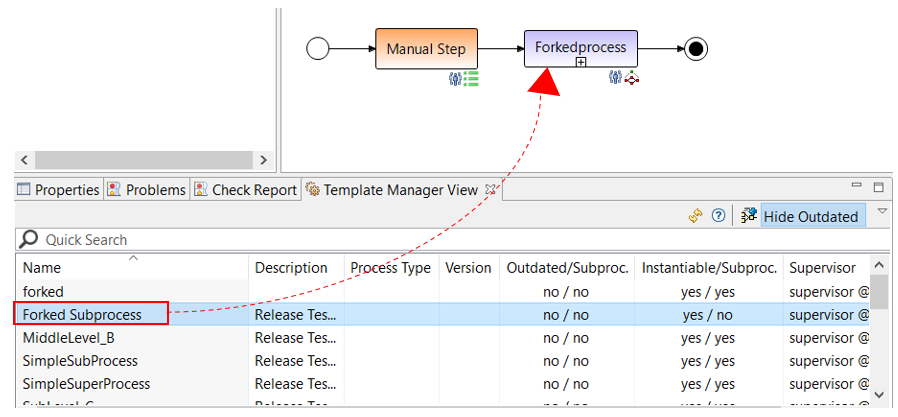
- Both the referenced and the forked processes can only be integrated from the template manager.
In the case of forked-insertion, the parent and child processes are executed in parallel, and the execution branches out. In this respect, forked is not an ordinary subprocess but a called process that runs in parallel.
Delete Template
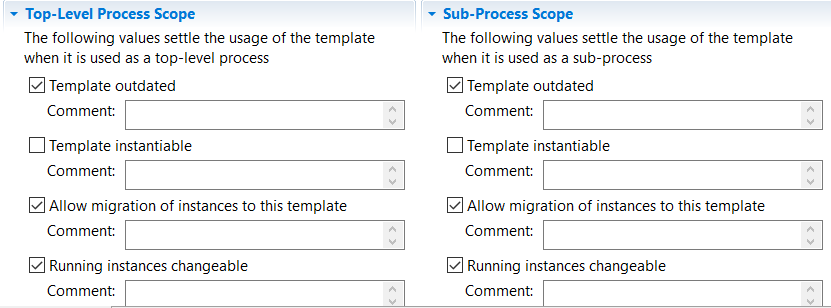
If a process template is no longer used, it is set to the OUTDATED state. This corresponds logically to their deletion. However you also have to set the template to not instantiable as well as top level (Top-Level Process Scope) and subprocess (Sub-Process Scope) as shown in next image.
Another advantage of the subprocesses in addition to the clarity in templates is their reusability. A subprocess no matter what type can be reused and called by several processes.
Parameters in Subprocesses¶
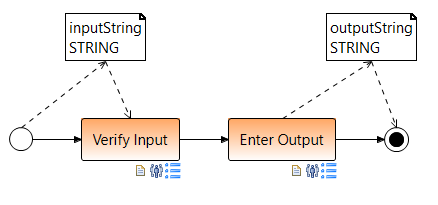
Just like activities, subprocesses can also have input/output parameters. Subprocess nodes can only access the data elements of your own process template and not those of the parent process. However, the parent process can pass the data elements to subprocess. Then all these data elements become input parameters of the subprocess which the start node writes. After writing the input parameters of the process, the start node is terminated and normal execution continues. In this way, the values of the input parameters are available to all process steps of the subprocess via the normal data flow. Output parameters are accordingly all of the end node read data items. The execution of the end node in subprocesses includes writing the Output parameters in the parent process. The output parameters are then available to the parent process.
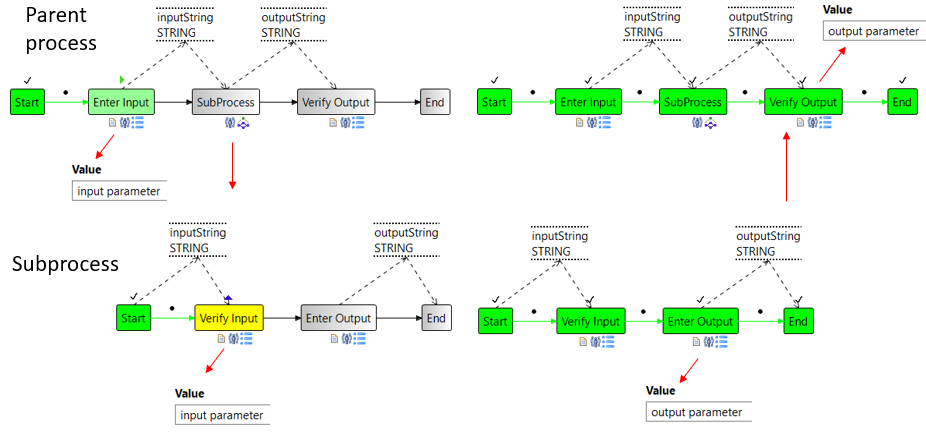
In previous image the parent process writes the verified from parent process.
However in the case of forked templates the corresponding node in the parent process is also immediately after the start of the forked process instance terminates and not only when the forked process instance has completed. Obviously, the output parameters of such subprocess instances cannot be in the parent process because they are only available with a delay and asynchronously.
SAR (staff assignment rule) in Subprocess¶
In addition to the normal input/output parameters of activities and subprocesses, there are special input parameters for nodes (system parameters). This Parameters are not used to supply the execution of the process, but rather from node attributes, for example to resolve dependencies on staff assignments rule.
With the help of these parameters you can transfer the Agent-ID from the parent process to the subprocess so that the steps in the subprocess are carried out by the same agent as in the parent process. In the following we will show you how to do this. But A few tricks are necessary for that. For example, we need an intermediate step to pass the Agent-ID on to the subprocess, which we will delete later.
Create Subprocess and enter parameterized SAR¶
-
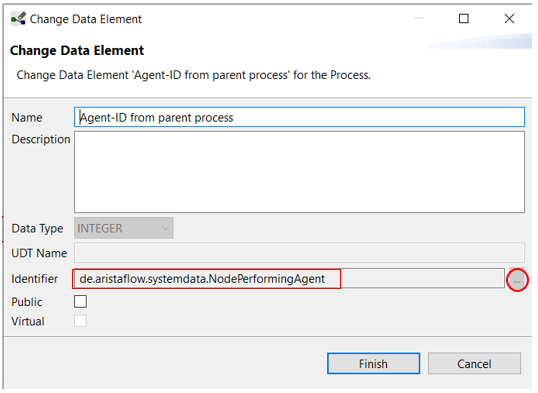
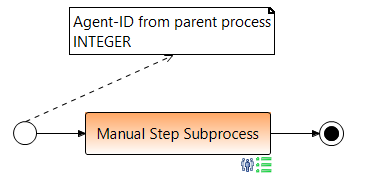
In the subprocess you create a data element for the agent ID, which will later get its value from the parent process. Connect the data element to the start node. When creating the data element, set the value for "Identifier" to de.aristaflow.systemdata.NodePerformingAgent.
-
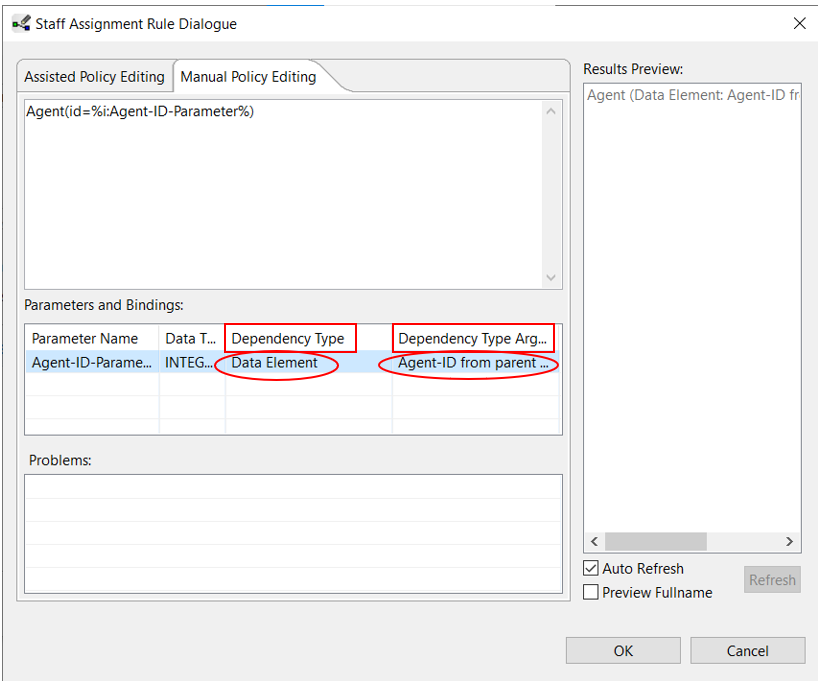
For the processstep Manual Step Subprocess go to the Staff Assignment Rule dialog and switch to Manual Policy Editing. Enter the following parameterized text as Policy:
Agent(id=%i:Agent-ID-Parameter%)
In the lower area, set Dependency Type to Data Element and select the newly created data element as the Dependency Type Argument.
Create input parameter for subprocess in parent process¶
-
In the higher-level process, the subprocess now requires a further input parameter for its new data element Agent-ID from parent process. The parameter should now contain the ID of the agent who carries out the processtep Manual Step.
To do this, we first create an additional dummy step in order to access this data.

-
Then we have to take the Agent-ID from the previous step Manual Step. Therefore open the Staff Assignment Rule dialog for the Dummy step and select the Agent from NodePerforming-AgentID and Manual Step(...) via Conditions. Then click on Add dependency.
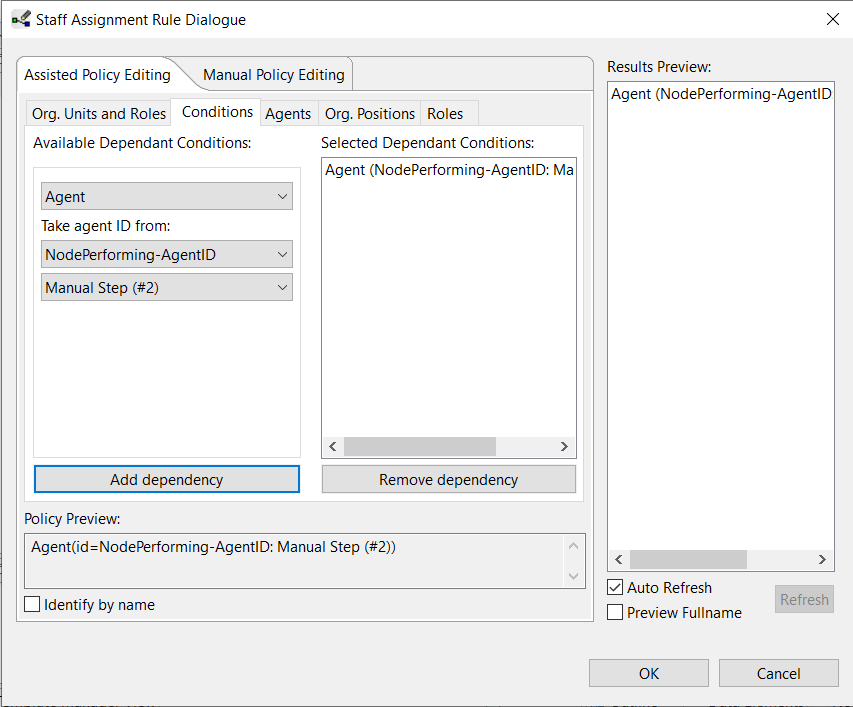
Connect input parameter to subprocess¶
-
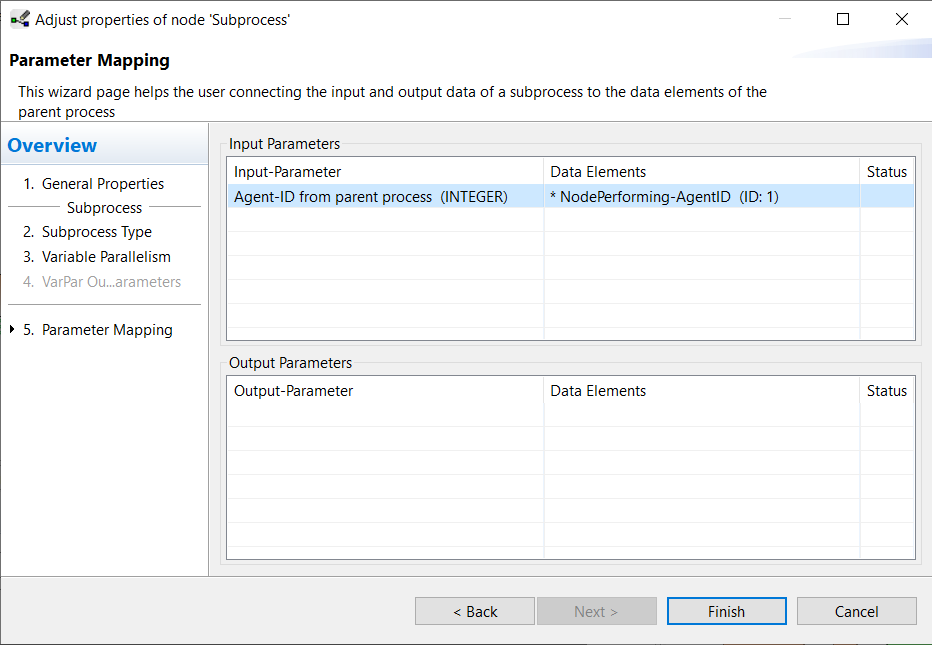
A system data flow for the Agent-ID has now been created in the background. Then you can connect the input parameter for the subprocess with the system data element NodePerforming-AgentID. To do that open the wizard for the subprocess and on page 5 Parameter Mapping connect the input parameter as shown in the next image.
 The result now looks like this:
The result now looks like this:
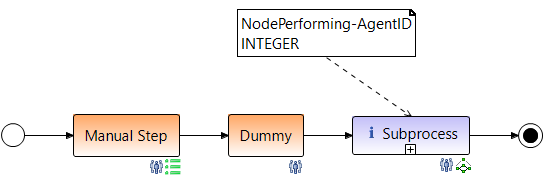
-
Then you can delete the dummy step.
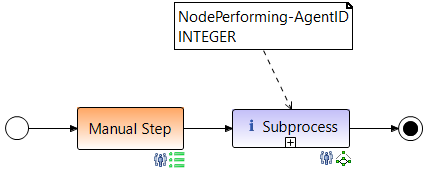
The data element NodePerforming-AgentID can now be renamed as desired (e.g. to AgentID parent process) in order to make the process easier to understand.